- print:
awk 如只有 Pattern(判斷式)其〝{Actions}〞部分是可省略,如省略時預設動作是〝print $0〞,例如 awk '/regex1/,/regex2/{print $0}' file 為列出檔案中符合正規表示法〝regex1〞到〝regex2〞之間所有的行,而〝print $0〞又可省略寫成〝print〞,甚至如預設動作為〝print〞,print 也可省略;所以下列 3 行指令是一樣的 。
awk '/regex1/,/regex2/{print $0}' file
awk '/regex1/,/regex2/{print}' file
awk '/regex1/,/regex2/'file (此例同等用 sed 寫成 sed '/regex1/,/regex2/!d' file)
例:$ awk '/^ayy*/,/^azz*/' /usr/share/dict/linux.words ←列出字典中 ay 到 az 開頭的所有的單字
print 內的逗號〝,〞代表輸出欄位間隔(Output Field Separator〝OFS〞)預設為空白是可以變更的,如下例 。
例:$ awk 'BEGIN {print "hello","awk"}' ←print 內的逗號〝,〞代表一個輸出欄位間隔,預設為空白
hello awk
$ awk 'BEGIN {OFS="<-->";print "hello","awk"}' ←更改輸出欄位間隔為〝<-->〞(輸出欄位間隔的內建變數為〝OFS〞)
hello<-->awk
而 print 預設的列間隔為 newline,可由內建變數〝ORS〞來變更,例如要輸出 DOS/Windows 格式的文字檔可設〝ORS=\r\n〞,例如 awk 'BEGIN {ORS="\r\n"}{print}' unix_file > dos_file 可模擬指令 unix2dos 。
print 預設的數值輸出格式為〝%.6g〞(小數點以下 6 位數的科學符號或浮點,參考 printf),如有必要可改其內建變數〝OFMT〞來變更位數或浮點(floating)或整數(integer)等。
例:$ awk 'BEGIN{print 0123456789.0123456789}' ←預設輸出為 6 位數的科學符號
1.23457e+08
$ awk 'BEGIN{OFMT="%.3f";print 0123456789.0123456789}' ←改小數點三位的浮點輸出
123456789.012
$ awk 'BEGIN{OFMT="%d";print 0123456789.0123456789}' ←改整數輸出
123456789
其他 print 用法參考基本用法的範例。
- printf:
如果要更進一步控制輸出格式,awk 提供幾乎和 C 語言一樣語法的 printf ( ) 指令,如下例。
例:$ awk 'BEGIN{ printf ("%d %s %1.2f\n",2,"Cheeseburgers",4.699)}'
2 Cheeseburgers 4.70
如果不熟 C 語言一眼不易理解這種外星文,printf 如下圖所示,引號「" "」右邊的東東依序各自找引號「" "」內的〝%〞對號入座,且 printf 不受輸出列間隔(內建變數的 ORS)控制,故如要換行要自行加入代表換行的〝\n〞。
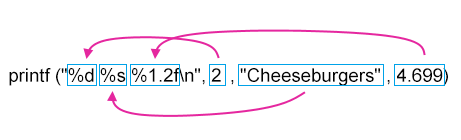
而〝%〞右側的〝d〞或〝s〞為輸出的資料型別(data types),常用的資料型別如下:
awk printf format 符號 資料型別 %c ASCII 字元 %d 整數 %e 科學符號 %f 浮點 %g awk 自動判斷使用科學符號或浮點 %o 八進位制 %s 字串 %x 十六進位制
除了可指定輸出的資料型別外還可指定資料的寬度,如上例的〝%1.2f〞為浮點,但寬度為一位數的整數和二位數的小數(〝.〞左邊為整數寬度,右邊為小數寬度)。 如省略寬度則由系統決定,如下例:
awk printf format for width 符號 資料型別 %f 不指定寬度的浮點(系統預設) %3d 3位數的整數 %.2f 兩位的小數寬度的浮點 %2.f 兩位的整數寬度的浮點
例:$ awk 'BEGIN{ printf ("%f \n",4.699)}' ←只指定浮點,但不指定寬度
4.699000
$ awk 'BEGIN{ printf ("%.2f \n",4.699)}' ←兩位的小數寬度
4.70
$ awk 'BEGIN{ printf ("%2.f \n",4.699)}' ←只用浮點的整數部分(自動四捨五入)
5
$ awk 'BEGIN{ printf ("%3d \n",4.699)}' ←三位數的整數(無條件捨去小數)
4
由於系統預設的輸出是靠右,可在〝%〞後接〝-〞號寫成〝%-〞強制靠左輸出。
例:$ echo 65 66| awk '{printf ("%10c%10c \n",$1,$2)}' ←輸出 10 位寬度的 ASCII 65 & 66 (靠右輸出)
A B
$ echo 65 66| awk '{printf ("%10c%-10c \n",$1,$2)}' ←強迫第二個字元靠左輸出
AB
awk 除了提供以數字為索引(index)的傳統矩陣(arrays)外最特別和最有威力的部分就是還支援〝關聯矩陣〞(Associative Arrays),這種型態的矩陣是傳統 C 程式語言所沒有但也是 awk 特別的地方。
什麼是關聯矩陣?關聯矩陣就是以〝字串〞來當索引,而不似傳統 C 語言以數字為索引。關聯矩陣對傳統程式語言的使用者可能有點文化差異,故我們循序漸進來一步步實驗和說明。
關聯矩陣也是無型別的自定變數,和自定變數的差別為其記憶體是連續的,如把 MS office 的 Excel 想像為一個關聯矩陣,一個關聯矩陣就是一個 Excel 的〝工作表〞(sheet),而 Excel 的索引如〝A1〞,A2〞,〝B1〞,B2〞等,在關聯矩陣是用字串來當索引。
例如有一關聯矩陣為名稱為〝color〞(不用宣告和定義其大小就可直接用),寫入關聯矩陣語法為 矩陣名[索引字串]=內容。
如下為寫入關聯矩陣二筆資料:
color ["RED"]=2.1
color ["BLUE"]="TV"
上述直接想像為 Excel 工作表,(但只有一維)其內容如下:
| RED | BLUE | ←索引字串 |
| 2.1 | "TV" | ←內容 |
要如要取出關聯矩陣儲存格(cell)的內容格式為矩陣名[索引字串],例如〝color["RED"]〞。下例為寫入關聯矩陣和印出內容
| $ awk 'BEGIN{color["RED"]=2.1;color["BLUE"]="TV";print color["RED"],color["BLUE"]}' 2.1 TV ←color["RED"] 內容為〝2.1〞& color["BLUE"] 內容為〝TV〞 |
Excel 看工作表就可知那些儲存格存了資料,但我怎知關聯矩陣裡存了多少資料和有那些索引字串呢?關聯矩陣提供如下語法來存取全部的矩陣。
for (index_variable in array) do something with array[index_variable] 。
套用上一範例我要把關聯矩陣〝color〞內容全列印出來,寫法為〝for (i in color) print i,color[i]〞,實作如下:
| $ awk 'BEGIN{color["RED"]=2.1;color["BLUE"]="TV";for (i in color) print i,color[i]}' BLUE TV RED 2.1 |
上例中指令〝for (i in color)〞(變數〝i〞名稱可自取)會自動搜索整個矩陣〝color〞,如矩陣內有放東西,則會把索引的字串存入變數〝i〞,故上例〝print i〞會輸出索引字串,而〝print color[i]〞會輸出以字串當索引的內容。(有一點要注意的地方為〝for (i in color) print i〞輸出的順序是隨機的)。
那要如何應用關聯矩陣呢?看下例就會知道關聯矩陣的好處,如下有一文字資料檔〝parts.db〞,為某電腦賣場週邊可選的顏色。
| $ cat parts.db KEYBOARD white black MOUSE blue red black white yellow CASE black MONITOR white silver red |
而我想統計每一種顏色出現的次數,我用關聯矩陣可很簡單的完成,如下例:
| $ cat awk_scr4 ←統計每一種顏色出現的次數的程式 { for( i=2; i<=NF; i++ ) color[$i]++ #←同等 color[$i] = color[$i] +1 } END { for( j in color ) printf( "%10s %d \n", j, color[j] ) } $ awk -f awk_scr4 parts.db ←執行〝awk_scr4〞來統計檔案〝parts.db〞 red 2 white 3 black 3 blue 1 silver 1 yellow 1 |
上例程式如何解讀呢?程式片段〝for( i=2; i<=NF; i++)〞因欄位〝$1〞記載的不是顏色,故 for 迴圈從 2 開始且每一行的欄位不是固定的,所以可以巧妙的用內建變數的〝NF〞,讓迴圈止於〝NF〞。
迴圈內的〝color[$i]++〞,為先假設一開始執行時,讀入〝parts.db〞第一行的〝$1〞=字串〝white〞,故以字串當索引時執行 color[white]++ 此時 color[white] 的值等於 1。
而讀入第二行時欄位 4 的〝$5〞又是字串〝white〞,故再執行 color[white]++ 時 color[white] 的值等於 2,如此一直循環下去就可統計每一字串出現的次數。
此例如不用關聯矩陣來完成,程式一定又臭又長。
在介紹自定變數時有用九九乘法表來示範二維矩陣,但事實上 awk 並沒支援二維矩陣,而是巧妙的用關聯矩陣來模擬二維矩陣。
例如二維矩陣 arrayA[3,7] 其數字索引會被轉換成字串索引的 arrayA["3\0347"] ,其中綠底〝\034〞為內建變數〝SUBSEP〞所定義的,但如果和欲處理的資料有衝突可自行定義〝SUBSEP〞為其他值。
下例為實驗二維矩陣其實是關聯矩陣。
| $ awk 'BEGIN{arrayA[3,7]="INDIGO";print arrayA["3\0347"];print arrayA[3,7]}' INDIGO ←arrayA[3,7] 等於 arrayA["3\0347"] 故輸出結果是一樣的 INDIGO |
- delete 刪除矩陣:
由於矩陣很浪費 RAM,所以必要時可刪除矩陣的內容(一般矩陣或關聯矩陣皆可刪除),用法如下:
指令 note delete array_name 刪除整個矩陣 delete array_name["string"] 刪除關聯矩陣內的一個儲存格(一維) delete array_name[2,3] 刪除關聯矩陣內的一個儲存格(二維) delete array_name [10] 刪除關聯矩陣內的一個儲存格(一維)
例:$ cat awk_scr5
{
for( i=2; i<=NF; i++ )
color[$i]++
delete color ["yellow"] #←刪除關聯矩陣人的一個儲存格〝color ["yellow"]〞
}
以下略
awk 曾很流行並非浪得虛名,因 awk 可很輕易的執行系統程式,也可利用管線與重定向。
如下例修改自〝awk_scr4〞,把運算後的結果用重定向存成檔案。
例:
| $ cat awk_scr6 BEGIN { #←BEGIN 區塊 outfile = "result" } { #←主程式區塊 for( i=2; i<=NF; i++ ) color[$i]++ } END { #←END 區塊 for( j in color ) printf( "%10s %d \n", j, color[j] ) > outfile #←結果重定向到檔案 print "***** Result Statistics *****" > outfile #←輸出重定向到檔案 } $ awk -f awk_scr6 parts.db ←執行〝awk_scr6〞(檔案〝parts.db〞同關聯矩陣範例) $ cat result ←查看檔案〝result〞 red 2 white 3 black 3 blue 1 silver 1 yellow 1 ***** Result Statistics ***** |
上例重定向〝>〞和在 shell 內的重定向有點不一樣,awk script 所重定向的檔案如一開始已存在會刪除該檔再建立一新的檔案,但該檔建立後的後續動作〝>〞會被當累加重定向〝>>〞處理。
如要在 awk 內執行系統指令也很簡單用指令〝system ("COMMAND")〞即可,上例程式〝awk_scr6〞因把輸出結果直接重定向成檔案,如我要要螢幕也有輸出,只要再加 cat 指令即可。(下例 awk_scr7)
例:
| $ cat awk_scr7 略 (BEGIN 和主程式區塊同〝awk_scr6〞) END { for( j in color ) printf( "%10s %d \n", j, color[j] ) > outfile print "***** Result Statistics *****" > outfile system ("cat "outfile) # ←執行系統指令〝cat〞 } |
上例的〝awk_scr6〞和〝awk_scr7〞有建立檔案的敘述〝> outfile〞,正確的寫法是要在程式結束時用指令〝close("file")〞來關閉檔案,不然〝可能〞會有無法預期的 bug。(好比開門外出而沒關門,可能沒事也可能被小偷光顧無法預測)
為什麼要關閉檔案呢?因 awk 在建立檔案時內部會對該檔建立一指標來連結,例如範例〝awk_scr6〞的符號〝>〞既可當重定向也可當累加重定向。原因為一開始時用〝>〞建立一檔案時會產生一指標來連結該檔,而如果指標的連結還存在後續的動作就自動變累加重定向。而指令〝close("file")〞會切斷檔案的指標連結。如果 awk 同時輸出許多的檔案而沒適當的用〝close("file")〞來關閉檔案 awk 會神經錯亂(因不知目前是在處理那個檔案或處理的檔是要重定向還是要累加。
一個很有用的判斷法為用如一個檔案已被建立如沒 close,後續的符號〝>〞為累加重定向,如有 close 則為建立該檔。下例〝awk_scr8〞和〝awk_scr9〞為最好的註解。
例:
| $ cat awk_scr8 BEGIN { print "abc" > "fileA" # ←建立檔案〝fileA〞 print "123" > "fileA" # ←累加重定向到〝fileA〞 } $ awk -f awk_scr8 $ cat fileA abc 123 $ cat awk_scr9 BEGIN { print "abc" > "fileA" # ←建立檔案〝fileA〞 close ("fileA") # ←關閉〝fileA〞(切斷檔案的指標連結) print "123" > "fileA" #指標連結被切斷,故此為建立檔案〝fileA〞 } $ awk -f awk_scr9 $ cat fileA 123 ←後面的結果蓋掉前一結果 |
close 有二種用法
- close ("file")
- close ("管線之後的 COMMAND")
第一種上例已使用了;第二種〝close (管線之後的 COMMAND)〞用於關閉經管線而建立的檔案,如下例〝awk_scr10〞修改自〝awk_scr9〞,主要差別為建立檔案之前經管線〝|〞後給 tr 把小寫改大寫,此時 close 檔案時要〝|〞之後的 COMMAND 一字不漏的寫進 close 內,否則會被視為 close 不同的檔案。
例如把小寫改大寫 tr 的寫法 tr 'a-z' 'A-Z' 和 tr '[:lower:]' '[:upper:]' 意義是一樣的,但對 close 來講是兩回事。
例:
| $ cat awk_scr10 BEGIN { print "abc" | "tr 'a-z' 'A-Z' > fileA" #←輸出經管線用 tr 把小寫改大寫 close ("tr 'a-z' 'A-Z' > fileA") #←close ("管線之後的 COMMAND")要一字不漏的寫進 close 內 system ("echo '123' >>" "fileA") #←〝fileA〞指標連結被切斷(close 了)故如要累加要用累加重定向〝>>〞 } $ awk -f awk_scr10 $ cat fileA ABC 123 |
上例中如在 debug 階段,不確定是否有正確的 close,可用 〝print close ("tr 'a-z' 'A-Z' > fileA")〞把 close 結果列印出來,如非 0 表示 close 有誤(可能打錯字),debug 完再把 print 拿掉。
awk 如要讀入的檔案超過二筆可寫成 awk file1 file2 而要讀入某系統指令的輸出超過兩個(如同時要讀入 ls 和 cat 的輸出)要怎麼寫呢?所以 awk 另提供〝getline〞指令來讀入系統指令的輸出或資料檔(主要用在讀入系統指令的輸出)。
getline 單獨使用是一次只讀一行目前的檔案到欄位變數內且如寫在主程式區是讀取下一行(因主程式已讀入目前的行)如下例:
例:
| $ seq 1 10 | awk 'BEGIN{getline;print}' ← 一次只讀一行 1 $ seq 1 10 | awk '{getline;print}' ←getline 如寫在主程式區是讀到下一行,所以輸出是跳行 2 4 6 8 10 |
一次只讀一行好像沒什麼用,所以一般的應用會用迴圈來讀取全部的檔案,但如何知迴圈次數? 原來 getline 毎次讀取會有一傳回值,其傳回值如下:
| getline 讀取 record |
|
| 成功 | 1 |
| 失敗 | -1 |
| 檔案結束 (〝EOF〞End Of File ) | 0 |
如下例為列印出 getline 的傳回值:
| $ seq 1 2 | awk 'BEGIN{print getline; print getline; print getline}' 1 ←getline 讀取成功 ($0=1) ,傳回值=1 1 ←getline 讀取成功 ($0=2) ,傳回值=1 0 ←getline 讀取失敗 ($0=EOF) ,傳回值=0 |
因 getline 讀取 record 如成功傳回值為 1,所以最簡單的方法為用 while 迴圈來重復執行 getline 來讀入全部資料,如下例:
例:
| $ seq 1 3 | awk 'BEGIN{while (getline) print}' ←因檔案結束時 getline 會 return 0 而跳出while
迴圈) 1 2 3 |
getline 除了可讀取目前的檔案更可配合管線或重定向來讀取資料檔或某指令的輸出,其可能的格式如下:
| getline [var] | 單獨使用,讀入目前的行存於欄位變數 |
| getline [var] < "FILE" | 從檔案讀取資料 |
| "COMMAND" | getline [var] | 從指令的輸出讀取資料 |
其中〝var〞為自定變數,如此變數已存在則〝var=$0〞,例如〝getline cell〞,此時變數〝cell=$0〞。
上表第二個〝getline [var] < "FILE"〞 為從檔案讀取資料,如檔案變為減號,例如〝getline < "-" 〞表示標準輸入可例用鍵盤輸入來和程式互動 。
上表第三個 〝"COMMAND" | getline [var]〞為從指令的輸出讀取資料,如套用上例重寫為 awk 'BEGIN{while ("seq 1 10" | getline) print}' ,就可不用經管線直接讀取指令 seq 1 10 的輸出。
如下範例分別讀入兩筆系統指令 ls -F 和 ls -A 的輸出,此例為先由指令 ls -F 把檔名經管線輸出到 awk,如經 awk 判斷該檔名是目錄再由 getline 讀取 ls -A 目錄的輸出來判斷工作目錄內有那些空目錄。
例:(判斷工作目錄內有那些空目錄)
| $ cat awk_scr11 { /\/$/ #←等於〝if ($0 ~/\/$/)〞(如果檔名是目錄,則繼續後續的動作,否則就處理下個檔名) { DirName=$0; while (("ls -A " DirName )| getline)#←用 getline 讀取系統指令〝ls -A〞的輸出 ListCount++ if (ListCount == 0) # ←假如 ListCount=0,一定是空目錄 {print "Directory --> "DirName" is empty"} ListCount=0 } } $ ls -F | awk -f awk_scr11 Directory --> dir2 is empty Directory -- >Documents is empty Directory --> Download is empty |
程式片段〝/\/$/〞為用正規表示法過濾來自 ls -F 的輸出(如為目錄會在檔名的最後加〝/〞,例如〝Documents/〞則繼續後續的動作)。
而程式片段〝while( "ls -A" | getline)〞如一開始 getline 就 return 0(檔案結束)而跳出迴圈,此時變數〝ListCount=0〞 則一定是空目錄。
除了簡單的四則運算,awk 也提供如下相當有用的運算式:
| 數學函數名 | 說明 | 範例 | 範例返回值 |
| % | 餘數 | 7%5 | 2 |
| ^ | 指數 | 2^3 | 8 |
如還不能符合需求還有方便的數學函數可供應用,每一個數學函數皆會返回一運算結果,返回的值可以指定給一變數;如〝A=int(3.8)〞或直接列印如〝print int(3.8)〞。
下表為 awk 支援的數學函數,函數中的〝x〞或〝y〞為輸入的值。
| 數學函數名 | 說明 | 範例 | 範例返回值 |
| sin( x ) | 正弦;其中 x 為弧度(弧度 = 角度/180 * PI) | sin (90 /180 * 3.4146) | 1 |
| cos( x ) | 餘弦;其中 x 為是弧度〝radian〞(弧度 = 角度/180 * PI) | cos (180/180*3.1416) | - 1 |
| atan2( y, x ) | 反正切 arc-tangent (y/x)反正切,傳回值為徑度 | atan2(30,45) | 0.588003 |
| exp( x ) | ex | exp(1) | 2.71828 |
| log( x ) | log e x | log (5) | 1.60994 |
| sqrt( x ) | 開根號 | sqrt (9) | 3 |
| int( x ) | 整數值(無條件去小數) | int (5.6) | 5 |
| rand( ) | 亂數;其中 0 <=亂數 < 1 | ||
| srand( [x] ) | 初始化 rand(),x 為亂數種子(seed),若省略,則會以執行時的時間+日期為起始的亂數種子 |
大部分的數學函數並沒什麼特別(不要問我數學,早還給老師了),這只介紹比較容易出錯和特殊的數學函數。
函數〝rand ()〞為亂數產生器,會隨機產生 0 到小於 1 的亂數,如下例為用 for 迴圈執行亂數產生器〝rand ()〞十次 。
例:
| $ awk 'BEGIN{for (i=1;i<=10;i++) print rand()}' 0.237788 0.291066 0.845814 0.152208 0.585537 0.193475 0.810623 0.173531 0.484983 0.151863 |
如上例表面上很亂,但如同一敘述多執行幾次會發現〝亂中有序〞,每次結果都一樣,原因為其演算法(algorithm)是固定的(如先以某一數當〝種子〞乘除某一數當亂數結果,再以此結果當亂數的種子一直運算下去),如不要有這種亂中有序的結果就加上另一函數〝srand()〞來改變其亂數種子。下例加為上〝srand()〞的用法。
例:
| $ awk 'BEGIN{srand();for (i=1;i<=10;i++) print rand()}' ←用〝srand()〞來初始化〝rand()〞的亂數種子 |
為什亂數產生器亂數範圍為〝0 <= rand() < 1〞?因為很容易套用到任何範圍,如我想用 awk 選號來簽台彩的〝大樂透〞49 選 6 ,因亂數範圍 < 1,故把亂數 * 49 取整數再 + 1 就對了。
下例為〝大樂透〞1~49 選 6 的電腦選號的實作。
例:
| $ awk 'BEGIN{srand();for (i=1;i<=6;i++) print int(rand()*49)+1}' ←〝明牌〞產生器 輸出略 |
如果有某個運算 awk 的函數沒支援,不得已可用 getline 利用外部指令來獲得運算結果,如下例為利用外部指令 echo 把二進制的 1100 bin 轉 10 進制放到變數〝dec〞。
例:
| $ awk 'BEGIN{"echo '$((2#1100))' " | getline dec ;print dec}' 12 |
awk 對字串的運算很友善,兩字串要相加,只要兩字串間用空白當隔格擺在一起即可,如二字串 "123" "abc" 產生的新字串為 "123abc"。
例:
| $ awk 'BEGIN{str1="123";str2= str1 "abc"; print str2}' 123abc |
字串不可能只要相加那麼單純的運算,故 awk 支援如下函數來更進一步對字串運算。
| 字串函數 | 說明 | 範例 | 範例返回值 |
| sub(regex, replace [,string] ) | 取代一筆字串 | st1="google goooogle" sub(/go+g/,"YAHOO",st1) |
1 st1="YAHOOle goooogle" |
| gsub regex,replace [,string ] ) | 取代全部字串 | st1="google goooogle" gsub(/go+g/,"YAHOO",st1) |
2 st1="YAHOOle YAHOOle" |
| index(string, substring) | 返回 substring 在 string 的位置, | index("this","is") | 3 |
| match(string,regex ) | 返回正規表示法匹配 string 的位置和長度 |
match("123xyzxyzxyz456",/(xyz)+/) | RSTART=4 RLENGTH=9 |
| length [(string)] | 返回字串長度 | length ("yahoo") | 5 |
| substr(string, index [,length] ) | 返回抽取後的字串 | substr("12345678',3,4} | "3456" |
| split(string, Array [,regex] ) | 將字串切割放入矩陣 | split("abc:de-fgh",arrA,/[:-]/ | arraA[1]="abc" arraA[2]="de" arraA[3]="fgh" |
| tolower( string ) | 大寫轉小寫 | tolower("Yahoo! 123") | "yahoo! 123" |
| toupper( string ) | 小寫轉大寫 | toupperr("Yahoo! 123") | "YAHOO! 123" |
| sprintf(format, data1,data2 ... ) | 將 printf 的輸出變新字串 | sprintf("%.4f",3.14162654) | 3.1416 |
字串函數不太容易根據函數名就會使用,如沒實例有時不易解釋,故依序照上表的範例簡單的說明一下和實測。
- sub(regex, replace [,string])取代一筆字串
此功能有點類似 sed 's/Regex/Replace/';原字串在 string 位置(如省略 string 為 $0),如符合正規表示法 regex 的匹配就以 replace 代替原字串,但只取代一次,並返回取代次數。
例:$ echo "google goooogle" |awk '{sub(/go+g/,"YAHOO");print }' ←如字串〝google goooogle〞可被正規表示法的〝go+g〞匹配,則用〝YAHOO〞取代之且只取代一次
YAHOOle goooogle
- gsub(regex,replace [,string ])取代全部字串
類似 sed 's/Regex/Replace/g' 同 sub( ) 但取代全部字串。
例:$ awk 'BEGIN{st1="google gooooogle";print gsub(/go+g/,"YAHOO",st1);print st1}'
2 ←加了〝print gsub()〞會返回取代的次數
YAHOOle YAHOOle ←取代結果
- index(String, substring)返回 substring 在 string 的位置
返回 substring 在 string 第一次出現的位置,若找不到返回 0。
例:$ echo 'this' | awk '{print index($0,"is")}'
3
- match(string,regex )返回正規表示法匹配 string 的位置和長度
和函數 index ()類似,但改用正規表示法匹配 string,且返回的位置和長度記錄在內建變數〝RSTART〞,〝RLENGTH〞。
例:$ echo '123xyzxyzxyz456' | awk '{match($0,/(xyz)+/); print RSTART,RLENGTH}'
4 9
- length [(string)]返回字串長度
如省略字串,則返回 $0 長度。
例:$ echo 'yahoo' | awk '{print length()}'
5
- substr(string, index [,length])返回抽取後的字串
返回字串由 index 起始算起,長度為 length 的字串,若省略 length 則到換行。
例:$ echo '123456789' | awk '{print substr($0,3,4)}'
3456
$ echo '123456789' | awk '{print substr($0,3)}'
3456789
- split(string, Array [,regex])將字串切割放入矩陣
將字串切割放入矩陣如省略最後一參數 [regex],預設切割字元為空白或 tab)
例:$ echo "abc de fgh" | awk '{split($0,arrayA);for (i in arrayA) print arrayA[i]}'
abc
de
fgh
- tolower(string)大寫轉小寫
- toupper(string)小寫轉大寫
例:$ awk 'BEGIN{print tolower("Yahoo! 123")}'
yahoo! 123
$ awk 'BEGIN{print toupper("Yahoo! 123")}'
YAHOO! 123
- sprintf(format, data1,data2... )將 printf 的輸出變新字串
printf 很容易變更輸出格式,而 sprintf 用法和 printf 一樣,但會把變更後的輸出格式轉變為字串。
如下例用 "%.4f" 四捨五入取小數以下四位。
例:$ echo '3.141592654' | awk '{new=sprintf("%.4f",$0);print new}'
3.1416
當 awk 提供的內建函數無法滿足需求時,還可自己寫自定函數(User-defined functions)。
自定函數語法為 function name (para 1,para 2, para 3...) {body-of-function [return value]}。
自定函數和傳統 C 語言的自定函數很類似,但不用宣告(declare),也無型別(typeless),但要在自定函數前加 meta-char〝function〞。
如下範例為一簡單的計算絕對值的函數〝abs()〞。
例:
| $ cat awk_abs { print abs($0) # ←call 自定絕對值函數〝abs()〞 } function abs (value) # ←自定的絕對值函數〝abs()〞 { if(value <0) value = value * (-1) return value # ←如有返回值用 return } $ echo "-13.38" | awk -f awk_abs 13.38 |