sed 每個參數之間預設分隔符號(delimiter)是用〝/〞來區別如 sed 's/OLD/NEW/g' flie,但如要搜尋樣板有〝/〞會和分隔符號混在一起如再加上跳脫字元〝\〞會變得好像火星文看不懂。
例如要把 Linux 路徑〝/abc/wxy〞改為 WINDOWS 路徑表示法的〝\abc\wxy〞,sed 的寫法為 sed 's/\//\\/g' ,真的不易一眼看出什麼是什麼,故 sed 可用除空白,換行(new line)以外的字元(英文字母或數字或符號皆可)來當分隔符號,只要前後一致即可。
例:
| $ echo 'this is a apple' | sed 's:a:AN:' ←將〝a〞改為〝AN〞(用〝:〞當 delimiter) this is AN apple $ echo '/home/frank/' | sed 's#/#\\#g' ←將〝/〞改為〝\〞(用〝#〞當 delimiter) \home\frank\ |
sed 位址的表示法可為行號或合法正規表示法的樣板,可為有起始和結束二個位址的範圍或只有單一位址(如第幾行或指定的樣板),有些 COMMAND 一定要配合單一位址,大部分的 COMMAND 位址的表示法為範圍,有些 COOMAND 如省略位址表示是全部(如上例搜尋並取代的 COMMAND〝s〞)。
位址範圍的用法各如下:
- 位址表示法:
為一個起始位址加上一個結束位址,兩者間以〝,〞分隔。如只有一個位址則為固定單一位址。
例:
$ sed '1,5 s/ [aA]/ one/' file ←將 1~5 行〝a〞或〝A〞改〝one〞
$ sed '5 s/ [aA]/ one/' file ←只將第 5 行〝a〞或〝A〞改〝one〞
$ sed 's/ [aA]/ one/' file ←省略位址,整個檔案〝a〞或〝A〞改〝one〞
檔案的開頭我們都知道是第一行,但檔案的結尾往往不知是第幾行,此時可用〝$〞來代表最後一行(和 vi 用法一樣,〝$〞代表最後一行)。
例:
$ sed '3,$ s/^can/CAN/' file ←將 3 行到最後一行開頭為〝can〞改大寫
- 樣板表示法:
有起始樣板和一結束樣板,每一樣板以成對的〝/〞括起來,起始樣板和結束樣板間以〝,〞分隔。
如只有一個樣板,表示任一行如匹配到此樣板都算。
例:
$ sed '/The/,/Whe/ s/ can/ CAN/g' < re.txt ←位址範圍從有〝The〞到〝When〞之間的行,字串〝can〞改〝CAN〞
$ sed '/[Cc]an$/ s/a/A/g' re.txt ←將符合〝[Cc]an$〞pattern 的那行〞a〞改〝A〞
思考題:如只匹配到起始樣板而沒找到結束樣板,或反之只有匹配到結束樣板而沒找到起始樣板會怎様呢?有興趣可自行玩看看。
- 混搭表示法:
sed 的位址表示法和樣板表示法是可混合使用超有彈性的。
例:
$ sed '2,/The/ s/[0-9]/#/g' re.txt ←第二行開始到符合〝The〞那行之間任何數字改為字串〝#〞
$ sed '/google/, $ s/a/A/g' re.txt ←從從有〝google〞那行到最後一行〝a〞改大寫
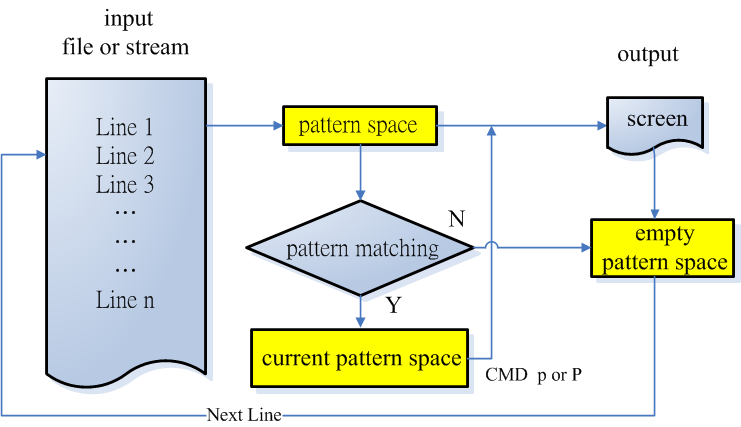
了解 OPTION 選項時先要了解 sed 指令的一些術語,才不會不知所云。 sed 的動作為一次只讀一行並去掉結尾的換行(EOL)到暫時的緩衝區(buffer)中,此暫時緩衝區稱為〝pattern space〞,接著處理完成後會把 pattern space 的內容送往螢幕後清空 pattern space 再去處理下一行,這樣不斷重複直到檔案結束。
如有內容符合搜尋的樣板之 pattern space 叫〝current pattern space〞,而 COMMAND〝p〞或〝P〞可令 sed 再輸出 current pattern space 到螢幕,其基本的動作流程如下。
sed 主要的選項如下:
| 語法: sed [-OPTION] [ADD1][,ADD2] [COMMAND] [/PATTERN][/REPLACEMENT]/[FLAG] [FILE]] | 註 | ||
| 指令名稱/功能/命令使用者 | 選項 | 功能 | |
| sed/ (stream editor)檔案字串修改/ Any |
-e | 執行 sed 的 script 語法 | 如沒使用〝-f〞選項此為預設選項 |
| -f | 選用外部的 script 檔來執行 | ||
| -n | 不輸出 pattern space 到螢幕 | ||
| -l # | 時常和 COMMAND l(小寫的〝L〞)一起使用時,指定每一行的長度 | # 為數字 | |
| -r | 使用延伸正規表示 | ||
| --help | 指令自帶說明 | ||
sed 有些選項可獨力運作,但有些選項單獨使用是沒什意義的,如 -n 或 -l 要配合其他 sed COMMAND 才有意義。各選項說明如下:
- -e: 執行 sed 的 script 語法。
sed 本來就是執行自己專屬的 script 腳本語言,故如都沒選項此為預設選項可省略。但如要搜尋和取代的樣板是多重的,或許多 COMMAND 合併使用,就一定要用〝-e〞選項。
例:$ echo 'this is a pen' | sed -e 's/t/T/' -e 's/pen/&cil/' ←將〝t〞改為〝T〞and〝pen〞改為〝pencil〞
This is a pencil
$ sed -e 's/a/A/' -e '/this/ q' -e 'l' MyFile ←許多 sed COMMAND 要使用,就一定要用〝-e〞選項
(此範例為把檔案〝MyFile〞內的文字〝a〞改〝A〞 直到某一行有字串〝this〞就結束 & 列出不顯示的字元)
- -f: 選用外部的 script 檔來執行。
如 sed 要處理的任務是多重的,此時可把毎一任務一一寫在一起存成一外部 script 檔,再用選項〝-f〞來指定此外部 script 檔即可。
這樣做的好處是規則改變時只要改此外部 script 檔即可,或寫許多 script 檔來處理不同的需求。
例:$ cat sed_scr ←例如有一外部 script 檔〝sed_scr〞功能為把 a~d 改大寫
s/a/A/g
s/b/B/g
s/c/C/g
s/d/D/g
$ echo 'abcdefg' | sed -f sed_scr
ABCDefg
例:$ sed -f sed_scr < MyFile > TargetFile ←用外部 script 檔〝sed_scr〞處理檔案〝MyFile〞處理後存成〝TargetFile〞
- -n: 不輸出 pattern space 到螢幕。
因 sed 處理完成一行後會把 pattern space 的內容送往螢幕後清空,故如單獨使用選項〝-n〞連 pattern space 也不輸往螢幕故輸出什麼也沒有,故選項〝-n〞一般要配合其他的 sed FLAG 使用才有意義。
一般是配合 sed FLAG〝p〞只列出 current pattern space(符合樣板的 pattern),才不會不符合的 pattern 也往螢幕送,此時 sed 的行為可取代 grep。
例:$ ls -d /etc/* | sed -n '/[A-Z][0-9]/ p' ←選項〝-n〞配合 FLAG〝p〞只列出符合樣板的行(類似指令〝grep〞)
/etc/X11
$ echo -e 'Line1\nLine2\nLine3' | sed -n 's/Line2/Line two/p' ←只列出有改變的行
Line two
- -l: 指定每一行的長度。
選項〝-l〞(小寫的 L)這選項是配合 COMMAND〝l〞(小寫的 L)使用,因 sed COMMAND〝l〞為把一些 ASCII 控制字元以〝\a〞、〝\b〞、〝\t〞,方式列出,但 ASCII 的控制字元大部分是用來文字定位或排縮,把定位功能取消列印出來可能會影響文字行的長度,故用選項〝-l〞來指定輸出到螢幕的長度。
例:$ echo -e 'This\tIs\tA\tDog' | sed -nl 10 'l' ←指定換行的長度=10
This\tIs\
\tA\tDog$
- -r: 使用延伸正規表示法解讀。
預設的情形下,sed 的樣板(pattern)只解讀正規表示法,加選項〝-r〞才會去以延伸正規表示法去解讀樣板。此時如樣板內有如〝?〞,〝+〞 等符號會被認為是延伸正規表示法的 meta-charaters(表示字元).不同的解讀結果可是差很多。
例:$ echo 'Why an apple $9.99?' | sed 's/99?/88/g' ←將字串〝99?〞改為〝88〞
Why an apple $9.88
上例中樣板〝99?〞如加選項〝-r〞強迫用延伸正規表示法來解讀是匹配字串〝9〞或〝99〞,結果可能很不一樣(下例)。
$ echo 'Why an apple $9.99?' | sed -r 's/99?/88/g' ←加選項〝-r〞用延伸正規表示法
Why an apple $88.88?
sed FLAG 主要為進一步的控制取代樣板(pattern)的行為,前面我們已用過 FLAG 中的〝g〞(global replacement)和〝p〞(print)。這兩個 FLAG 是最常使用的,其他的 FLAG 並不常用,了解一下即可,全部的 FLAG 用途如下:
| Sed Flags | |
| [g][ 數字] | 全部取代或指定取代第幾個 |
| I | 忽略 pattern 大小寫 |
| p | 列印 |
| w | 寫入檔案 |
- g: 全部取代。
預設 sed 只取代搜尋/取代到第一個樣板此行就停止而去處理下一行,如有此 FLAG 則全部搜尋和取代。
例:$ echo 'this is an issue' | sed 's/is/IS/' ←〝is〞→〝IS〞,但預設只取代搜尋/取代到第一個 pattern
thIS is an issue
$ echo 'this is an issue' | sed 's/is/IS/g' ←加 flag〝g〞全部取代
thIS IS an ISsue
另 FLAG 也可用數字,如是數字表示只搜尋/取代第 N 個數字所指示的那個樣板。
例:$ echo 'aaaaa aaaaa' | sed 's/a/A/3' ←第 3 個符合的樣本才取代
aaAaa aaaaa
FLAG〝g〞和數字合併使用也可以,在 FLAG〝g〞前加數字,例如 3g 表示第 3 個符合的 pattern 才開始全部取代。
例:$ echo 'aaaaa aaaaa' | sed 's/a/A/3g' ←第 3 個符合的樣本才開始取代
aaAAA AAAAA
- I: 忽略 pattern 大小寫。
此 FLAG 主要對樣板的大小寫一視同仁。
例:$ echo 'this is an apple' | sed 's/APPLE/banana/I'
this is an banana
- p: 列印 current pattern space。
如沒此 FLAG,sed 只輸出 pattern space,如加了〝p〞FLAG 會再輸出 current pattern space,一般此 FLAG 是和選項〝-n〞合作只輸出符合的 pattern (current pattern space)。
例:$ echo 'this is a pen' | sed 's/pen/pencil/p'
this is a pencil ←此行輸出是 pattern space 的內容
this is a pencil ←此行輸出是 current pattern space 的內容
$ echo -e 'Line1\nLine2\nLine3' | sed -n '/[13]/p' ←和選項〝-n〞配合只列出符合的樣板
Line 1
Line 3
- w: 寫入檔案。
和 FLAG〝p〞類似,差別是只 FLAG〝w〞FILE 為將 current pattern space 寫人檔案 FILE。
例:$ man cp | sed 's/copy/{&}/w cp.txt' ←將 man page 中的〝copy〞字串加上大括號〝{}〞寫入檔案〝cp.txt〞
例:
| $ man cp | sed -n 's/COPY/{&}/Igpw cp.txt' ←FLAG 不只一個時,如有和檔案有關 FLAG(如〝w〞) 一定要加在最後 |
sed 具有相當程度的可程式化(programmable),你可以不用會任何程式語言但只要會 sed 就可完成大部分文字的修改需求。但就和其他程式語言一樣,可程式化就一定有流程控制(Control flow),還好 sed 的流程控制相當簡單且沒幾個(相較其他程式語言)。
sed 相關流程控制為 sed COMMAND 的一部分,因自成一格,故我把它分開來說明,其語法如下。
- ! 和 #: 禁能和註解。
例如有一外部的 sed script 檔,有暫時不執行的項目,只要在該行前加〝!〞,該行就不會被執行(disable)。另〝#〞開頭的行表示此行為註解也不會被執行。
例:$ cat sed_scr1
# conver a..d to A..D ←此行為註解,不會被執行
s/a/A/g
!s/b/B/g #←以〝!〞開頭的行不會被執行
#s/c/C/g #←〝#〞開頭的行被當註解,不會被執行
s/d/D/g
$ echo 'abcdefg' | sed -f sed_scr1
AbcDefg
如〝!〞加在命令的地方為該命令的反動作,例如 sed '/pattern/ d' 為刪除符合 pattern 那行,如寫成 sed '/pattern/ !d' 則為刪除不符合 pattern 的所有行。
例:$ sed -n '10,15 !p' MyFile ←不輸出檔案 10~15 行
$ cat MyFile | sed -n '/Apple/ !=' ←列出字串沒有〝Apple〞的行數
- {}: 命令套餐。
sed 會把〝{}〞內的各敘述當成一命令套餐視為是一體的。就像麥當勞套餐一樣內有薯條漢堡和可樂等是一體的;sed〝{}〞內的套餐內容是你自己然決定的 。
例如上例用命令套餐改寫如下例。
例:$ cat sed_scr2
# grouping with {}
{ #←套餐開始
s/a/A/g
!s/b/B/g
#s/c/C/g
s/d/D/g
} #←套餐結束
$ echo 'abcdefg' | sed -f sed_scr2
AbcDefg
上例用命令套餐好像多此一舉,有沒用把各命令用〝{}〞括起來結果都一樣?但如加上位址範圍用命令套餐的優點就出來了,因位址範圍後面接的命令只能一項,解除此限制可用〝{}〞把好幾種命令打包成〝一個〞。如下例為用命令套餐只處理某檔案 1~3 行。
例:$ cat sed_scr3
# grouping with {}
1,3 {
s/a/A/g
!s/b/B/g
#s/c/C/g
s/d/D/g
}
$ head 3 /etc/passwd | sed -f sed_scr3
root:x:0:0:root:/root:/bin/bAsh
bin:x:1:1:bin:/bin:/sbin/nologin
DAemon:x:2:2:DAemon:/sbin:/sbin/nologin
語法中有一點要特別注意即位址範圍和〝{〞要寫在同一行,原因為位址範圍後面緊接命令,或接套餐命令開頭的〝{〞。
如下為錯誤的表示法
例:$ cat sed_scr4
/hello/
{ #←有誤!因套餐開始的〝{〞要和位址範圍寫在同一行
s/a/A/
}
另外〝{}〞也可好幾層寫成巢狀,如下例為 10 到最後一行,樣板〝chaper 1〞到〝chaper 2〞之間 a 和 b 改大寫。
例:$ cat sed_scr5
# grouping with nest burly braces
10,$ {
/chapter 1/,/chapter 2/ {
s/a/A/g
s/b/B/g
}
}
- label: 標籤
。
冒號〝:〞後面接任何可顯示的字串或字元即標籤 label(例〝:upper〞),主要為提供 sed COMMAND〝b〞或〝t〞或〝T〞的進入點。
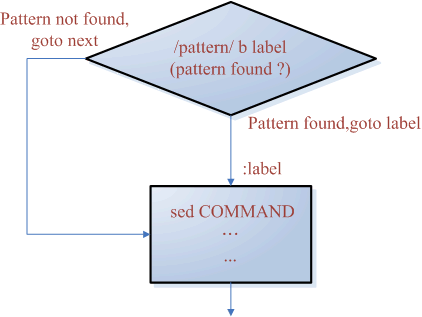
- b label : 跳躍到標籤。
〝b〞後面接 label(例〝b upper〞)為跳躍到標籤的進入點。跳躍可分〝無條件跳躍〞和〝樣板條件跳躍〞。
例如〝b upper〞為無條件跳躍到標籤〝upper〞。
而〝/patter/ upper〞為樣板條件跳躍,意義為如符合樣板(patter)則跳到標籤〝upper〞,否則則執行下一行。
其流程圖如下:
例:$ cat sed_scr6
# if pattern 'google' found,char "a"->"A" else "b"->"B"
/google/ b capitalA #←樣板條件跳躍,如符合'google'則跳躍到 label 'capitalA'
{
s/b/B/g
b end #←無條件跳躍到 label 'end'
}
:capitalA #←label 'capitalA'
{
s/a/A/g
}
:end #←label 'end'
$ echo -e 'google abc\nyahoo abc' | sed -f sed_scr6
google Abc
yahoo aBc
- t label branch
此為樣板取代成功跳躍,即如樣板取代成功則跳到標籤,否則則執行下一行。
例:$ cat sed_scr7
s/g..g../GOOGLE/g
t capitalA #←如樣板取代成功則跳到標籤 'capitalA',否則則執行下一行
b end
:capitalA
s/a/A/g
:end
$ echo -e 'google abc\nyahoo abc' | sed -f sed_scr7
GOOGLE Abc
yahoo abc
- T label branch:
大寫 T 的 T lable branch 為樣板取代不成功則跳躍,否則則執行下一行。
因有時用負邏輯來寫,敘述可簡短一些,如上例用 T lable branch 重寫如下:
例:$ cat sed_scr8
s/g..g../GOOGLE/g
T end #←如樣板取代不成功則跳到標籤 'end'
s/a/A/g
:end
$ echo -e 'google abc\nyahoo abc' | sed -f sed_scr8
GOOGLE Abc
yahoo abc
前面我們已用過 sed COMMAND〝s〞,因 sed 功能強大故相對的 COMMAND 也不少,還好大部分的 COMMAND 和 vi 相通。
可能的 sed COMMAND 如下:
| sed 指令 | 位址 | 功能 | 註 |
| :label | 標籤 | 參考流程控制 | |
| # | 註解 | 參考流程控制 | |
| ! | 禁能 | 參考流程控制 | |
| {} | 命令套餐 | 參考流程控制 | |
| b label | 無條件跳躍或樣板條件跳躍到 label | 參考流程控制 | |
| t label | 樣板取代成功跳躍 | 參考流程控制 | |
| T label | 樣板取代不成功跳躍 | 參考流程控制 | |
| = | 範圍 | 列印行號 | |
| a , i 或 a\, i\ | 範圍 | 插入文字 | |
| c 或 c\ | 範圍 | 取代行 | |
| d | 範圍 | 刪除 pattern space 或指定的行 | |
| D | 範圍 | 刪除 pattern spac內的第一個字元一直到換行 | |
| g | 範圍 | hold space 複製到 pattern space | |
| G | 範圍 | hold space 添加到 pattern space | |
| h | 範圍 | pattern space 複製到 hold space | |
| H | 範圍 | pattern space 添加到 hold space | |
| l | 範圍 | (小寫的 L)強制列印不顯示的字元 | |
| n | 範圍 | 讀取下一行 | |
| N | 範圍 | 添加下一行到 pattern space | |
| p | 範圍 | 列印 current pattern space | |
| P | 範圍 | 列印 current pattern space內的第一個字元一直到換行 | |
| q | 單一位址 | 立即離開 sed | |
| Q | 單一位址 | 立即離開 sed 但不輸出 current pattern space | |
| r | 單一位址 | 把檔案的內容插入文字 | |
| s | 範圍 | 搜尋/取代 | |
| w | 範圍 | 將 current pattern space 寫到檔案 | |
| x | 範圍 | pattern space 和 hold space 資料互換 | |
| y | 範圍 | 轉換字元 |
各別的 sed 命令說明如下:
- =: 列印行號。
有時我們想知道某 pattern 在文件中的第幾行出現,用〝=〞來列印還蠻方便的。
例:$ sed -n '/home/=' /etc/passwd ←列出檔案〝/etc/passwd〞有字串〝home〞 的行數
37
38
39
因在正規表示法中〝$〞代表結束/最後之意,故可用〝$=〞來列出某文件共有多少行。
例:$ man sed | sed -n '$=' ←列出 sed 的 man page 共有幾行
261
- a ,i 或 a\, i\: 插入文字。
sed 在某行或搜尋到的樣板的上一行或下一行插入文字,插在某行或樣板的下一行為 COMMAND〝a〞,反之插在樣板的上一行為〝i〞。
例:$ echo -e 'Line1\nLine2\nLine3' | sed '/Line2/ aINSERT' ←樣板〝Line2〞的下一行插入〝INSERT〞
Line1
Line2
INSERT ←插入的行
Line3
$ sed '6,$ aHello' MyFile ←檔案〝MyFile〞6 到最後一行各插入〝Hello〞
如要插入的行不只一行,只要插入換行即可。
例:$ echo -e 'Apple\nBanana\nCoconut' | sed '3 iOrange\nDurian' ←第三行之上插入二行
Apple
Banana
Orange ←插入的行
Durian ←插入的行
Cocount
如寫成外部的 script 檔,而欲插入的文字寫在 COMMAND〝a〞或〝i〞的下一行要寫成〝a\〞和〝i\〞,而插入的文字最後加〝\〞等於換行。
例:$ cat sed_scr9
/pattern/ a\
Insert line1 \
Insert Line2
- c 或 c\: 取代行。
以新文字行取代某範圍或符合 pattern 的行。
例:$ echo -e 'Line1\nLine2\nLine3' | sed '/2$/ cREPLACE LINE' ←以〝REPLACE LINE〞取代最後一字元為〝2〞的行
Line1
REPLACE LINE
Line3
$ echo -e '1\n2\n3\n4\n5' | sed '1,3 cREPLACE 1-3' ←以一行取代多行
REPLACE 1-3
4
5
COMMAND〝c〞用法和插入 COMMAND〝a〞或〝i〞類似可用換行字元〝\n〞或用〝c\〞。
- d: 刪除 pattern space 或指定的行。
例:$ sed '4,8 d/' MyFile ←刪除 4~8 行
$ sed '4,8 !d/' MyFile ←保留 4~8 行其餘皆刪除
$ sed '/pattern/ d' MyFile ←刪除匹配到 pattern 的行
$ sed '/pattern1/,/pattern2/ d' MyFile ←刪除匹配到 pattern1 到 pattern2 中間所有的行
$ sed '/^$/ d' ←刪除空白的行
- p: 列印 current pattern space
一般是配合選項〝-n〞使用,因選項〝-n〞為不輸出 pattern space 到螢幕,而 COMMAND〝p〞為列印 current pattern space,兩個一起使用就是列印符合搜尋樣板的 pattern 。
例:$ sed -n '5,12 p' file ←列印〝file〞 5~12 行
$ sed -n '/regex1/,/regex2/ p' file ←列印〝file〞符合正規表示法 regex1 到 regex2 間的行
- N,D 和 P: 多行編輯。
sed 的 COMMAND〝N〞、〝D〞和〝P〞這三個都大寫的命令主要是用來組合多行編輯,其功能各如下。
- N: 添加下一行到 pattern space。
由於 sed 為一次只讀一行並去掉結尾的換行到 pattern sapce,而處理下一行時 pattern space 為會把上一次內容清空換目前的行。
而命令〝N〞為不清空 pattern space 的情形下再追加下一行的內容到 pattern space,兩筆資料以換行字元〝\n〞(ASCII = 0AHEX) 隔開。
例如 echo -e 'LineA\nLineB' | sed 'N',而此時 pattern space 內的資料如下:
這樣就可把二行以上的資料放在 pattern space 來處理。L i n e A \n L i n e B
例:$ echo -e 'LineA\nLineB' | sed -e 'N' -e 's/\n/+/' ←用〝N〞讀下一行,再把換行字元〝\n〞改其他字串
LineA+LineB
上例常用來合併多行。
- D: 刪除 pattern space 內的第一個字元一直到第一個換行。
如有一 pattern space 內容如下:L i n e A \n L i n e B \n L i n e C
執行 COMMAND〝D〞後會刪除 pattern space 內的第一個字元一直到第一個換行字元〝\n〞。結果的 pattern space 如下:
LineA\nL i n e B \n L i n e C
例:$ echo -e 'LineA\nLineB\nLineC' | sed -e 'N' -e 'N' -e 'D' ←用二次〝N〞連讀二個下一行,再〝D〞刪除第一行
LineB
LineC
- P: 列印 current pattern space 內的第一個字元一直到換行。
sed 'P' 行為和 sed 'D' 很類似,只是把刪除動作改為列印。
例:$ echo -e 'LineA\nLineB\nLineC' | sed -e 'N' -e 'N' -ne 'P'
LineA
例:$ cat sed_scr10
/ID/{
N #if matching "ID" append the next line
/NAME/ {
N #if 2nd line matching "NAME" append next line again
/ADDRESS/ {
D #delete 1st matched line
}
}
}
$ echo -e 'ID:123\nNAME:abc\nADDRESS:taipei' | sed -f sed_scr10
NAME:abc ←ID 那行被刪了
ADDRESS:taipei
$ echo -e 'ID:123\nSEX:m\nADDRESS:taipei' | sed -f sed_scr10
ID:123 ←如樣板〝ID〞/〝NAME〞/〝ADDRESS〞 不是依序且是相鄰的行就不會被刪
SEX:m
ADDRESS:taipei
- N: 添加下一行到 pattern space。
- h,H 和 g,G 和 x: 交流 pattern space 和 hold space。
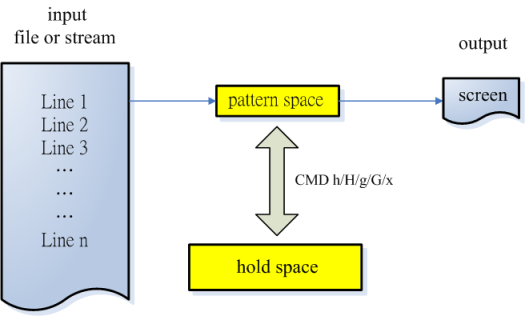
說明之前先了解一下 sed COMMAND h/H 和 g/G 和 x 會用到的〝hold space〞, hold space 和 pattern space 一樣是一緩衝區,但 hold space 的內容不直接輸出到螢幕,而是為專門提供某些 COMMAND (如 g/G/h/H/x)等在 pattern space 和 hold space 之間內容相互交流來增加檔案的編輯性,其流程如下 。
這幾個和 hold space 有關的 COMMAND 說明各名下:
- h: pattern space 複製到 hold space。
- H: pattern space 添加到 hold space。
如有一 hold space 內容如下:L i n e A
而 pattern space 內容如下:L i n e B
執行 COMMAND〝H〞後 hold space 結果如下,合併的 space 中間會加一個換行字元〝\n〞。
L i n e A \n L i n e B - g: hold space 複製到 pattern space。
- G: hold space 添加到 pattern space
例:$ cat sed_scr11
/ID/{
h # if matching "ID" pattern-space copy to hold-space
n # read next line
/NAME/ {
G # append hold-space to pattern-space
}
}
p # print the current-pattern-space
$ echo -e 'ID:123\nNAME:abc' | sed -nf sed_scr11
NAME:abc
ID:123
多行編輯相關命令(〝N〞、〝n〞、〝D〞和〝P〞等)配合 hold space 交流命令可創造許多異想不到的功能變化。[註]
- h: pattern space 複製到 hold space。
- l: 強制列印不顯示的字元。
有時可能會遇到明明檔案中有某字串,但用 sed 或 grep 都匹配不到,其中最可能的原因為檔案中有不會顯示的〝\a〞或〝\t〞等定位符號,或是在換行字元前多輸入了空白,如下例。
$ echo -e 'as can\aner can can a can '
as canner can can a can ←輸出看不出異常
$ echo -e 'as can\aner can can a can ' | sed -n '/can$ /p' ←因最後的〝can〞多打了一空白,故用正規表示法的〝can$〞會匹配不到
$ echo -e 'as can\aner can can a can ' | sed -n '/canner /p' ←因有不會顯示的〝\a〞,故也匹配不到
$ echo -e 'as can\aner can can a can ' | sed -n 'l' ←用 COMMAND〝l〞(小寫的 L)讓不顯示的字元現形
$ as can\aner can can a can $
所以 sed 'l' 是很有用的 debug 工具,COMMAND〝l〞 另一用法為配合 option -l 使用。
- q 或 Q: 立即離開 sed。
sed q 或 sed Q 為指定第幾行或匹配到某 pattern 就離開,至於 COMMAND〝Q〞和〝q〞的差別,看下例就明白,應不用說明了。
例:$ ls -l / | sed '/dev/ q'
total 142
drwxr-xr-x 2 root root 4096 2012-07-04 19:48 bin
drwxr-xr-x 4 root root 1024 2012-06-09 01:30 boot
drwxr-xr-x 13 root root 4060 2013-10-31 19:50 dev
$ ls -l / | sed '/dev/ Q'
total 142
drwxr-xr-x 2 root root 4096 2012-07-04 19:48 bin
drwxr-xr-x 4 root root 1024 2012-06-09 01:30 boot
例:$ sed '10 q' MyFile ←列出檔案前 10 行,此時行為等於指令〝head -n〞
$ sed -e 's/a/A/' -e '/Hello/ q' MyFile ←搜尋和取代,但遇到〝Hello〞就結束
- n: 讀取下一行。
把下一行寫入 pattern space。
例:
多行編輯時或用 COMMAND〝h〞存取 hold space,COMMAND〝n〞常是必要的元素。$ echo -e 'LineA\nLineB' | sed -e 'n' -ne 'p'
LineB
- r: 把檔案的內容插入文字。
和 COMMAND〝a〞有類似的行為,差別為插入文字的內容寫在一檔案。
例:$ sed '3 r INSERT.txt' MyFile ←檔案〝MyFile〞第三行插入另一檔案〝INSERT.txt〞的內容
$ cat MyFile | sed '/ch1/,/ch2/ r INSERT.txt' ←樣板〝ch1〞和〝ch2〞之間插入另一檔的內容
$ sed '/ch1/ r INSERT.txt' MyFile ←符合樣板〝ch1〞那行之下插入另一檔案的內容
- w: 將 current pattern space 寫到檔案。
一般用重定向寫入檔案會更用彈性,但如正在處理的檔案和要寫入的檔案是同一個,就非用不可。
例:$ cat fileA | sed 's/i/I/g' > fileB ←如處理的檔案和要儲存的檔案不同,建議用重定向
$ cat fileA | sed 's/i/I/g w fileA' ←COMMAND〝w〞主要同在正在處理的檔案和要寫入的檔案是同一個
- y: 轉換字元。
如果要把某一檔案的小寫全改大寫,用 COMMAND〝s〞可能會寫到瘋掉,用轉換字元 sed y// 就可輕鬆輕鬆的。
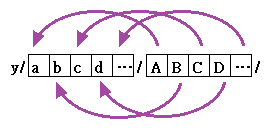
例如 〝y/abcd.../ABCD.../〞其動作如下,以後面的字元依序取代前面字元。
例:$ echo abcdefg | sed 'y/abc/ABC/'
ABCdefg
$ echo 'john smith' | sed 'y/nh/#&/'
jo&# smit&
$ echo '(2+3)*4' | sed 'y/()*/[]X/'
[2+3]X4