By default, sed uses the forward slash "/" as the delimiter to distinguish between each parameter, as seen in the command sed 's/OLD/NEW/g' FILE. However, when the search pattern itself contains forward slashes, it can become confusing to distinguish between the delimiter and the pattern. Moreover, if you need to use escape characters "\" to handle such situations, the command can become very cryptic and difficult to understand.
For example, if you want to convert a Linux path "/abc/wxy" to the Windows path representation "\abc\wxy," the sed command would look like sed 's/\//\\/g'. This usage can be difficult to read and understand at first glance.
To address this, sed allows you to use any character other than whitespace or newline as the delimiter. You can choose a delimiter that is not present in the search pattern or replacement string, and it should be the same character before and after the "s" command.
Examples:| $ echo 'this is a apple' | sed 's:a:AN:' ← Replace "a" with "AN" (using ":" as the delimiter) this is AN apple $ echo '/home/frank/' | sed 's#/#\\#g' ←Replace "/" with "\" (using "#" as the delimiter) \home\frank\ |
In sed, the address can be represented by line numbers or a valid regular expression pattern. It can be a range with two addresses (start and end), or it can be a single address (such as a specific line number or a specified pattern). Some COMMANDS in sed require a single address, while most commands use address ranges. In some COMMANDS, omitting the address represents the entire file (as seen in the previous example with the search and replace COMMAND "s").
The usage of address range is as follows:
- Address Representation:
It consists of a starting address followed by an ending address, separated by a comma ",". If there's only one address, it represents a fixed single address
Examples:
$ sed '1,5 s/ [aA]/ one/' file ←Replace "a" or "A" with "one" in lines 1 to 5
$ sed '5 s/ [aA]/ one/' file ←Only replace "a" or "A" with "one" in line 5
$ sed 's/ [aA]/ one/' file ←Omitting the address replaces "a" or "A" with "one" in the entire file
The beginning of a file is known to be the first line, but the end of a file is often unknown. In such cases, you can use "$" to represent the last line of the file (similar to the vi usage where "$" represents the last line).
Examples:
$ sed '3,$ s/^can/CAN/' file ←Replace "can" at the beginning of lines 3 to the end of the file with "CAN"
- Pattern Representation:
There is a starting pattern and an ending pattern, and each pattern is enclosed in a pair of slashes "/". The starting and ending patterns are separated by a comma ",". If there's only one pattern, it represents any line that matches the pattern.
Examples:
$ sed '/The/,/Whe/ s/ can/ CAN/g' < re.txt ← Address range from the line with "The" to the line with "Whe", replace "can" with "CAN"
$ sed '/[Cc]an$/ s/a/A/g' re.txt ←Replace "a" with "A" in the line that matches the pattern "[Cc]an$"
Think about this: What happens if the starting pattern is matched, but the ending pattern is not found, or vice versa? Feel free to try it out and see!
- Mix and Match Representation
In sed ,it is highly flexible to combine both address representation and pattern representation in a single command.
Examples:
$ sed '2,/The/ s/[0-9]/#/g' re.txt ← Replace any numbers with "#" from the second line to the line containing "The"
$ sed '/google/, $ s/a/A/g' re.txt ← Replace all occurrences of "a" with "A" from the line containing "google" to the last line
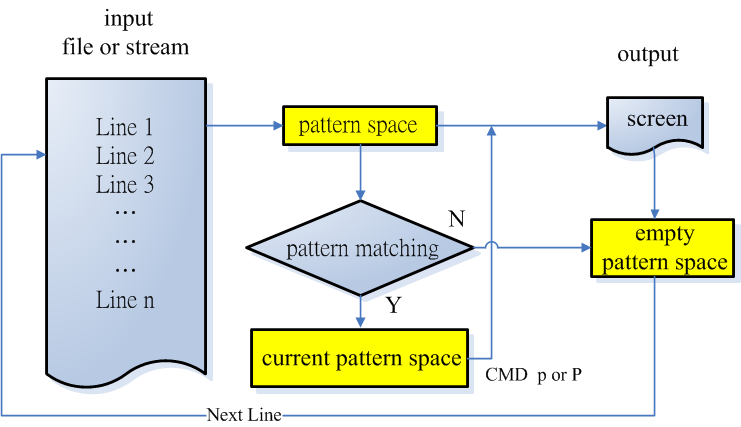
To understand the OPTIONS of the sed command, one must first grasp some terminology to avoid confusion. sed operates by reading one line at a time, removing the end-of-line (EOL) character, and placing it in a temporary buffer called the "pattern space." After processing, the content of the pattern space is sent to the screen, the pattern space is cleared, and then the next line is processed. This process continues until the end of the file is reached.
If the content matches the search pattern in the pattern space, it is called the "current pattern space." The COMMANDs "p" or "P" can be used to output the current pattern space to the screen. The basic workflow is as follows:
The main options of sed are as follows:
| Syntax:: sed [-OPTION] [ADD1][,ADD2] [COMMAND] [/PATTERN][/REPLACEMENT]/[FLAG] [FILE]] | Note | ||
| Command name/Function/Command user | options | Function | |
| sed/ stream editor/ Any |
-e | Execute the script syntax of sed | If the "-f" option is not used, this is the default option |
| -f | Use an external script file to execute | ||
| -n | Do not output the pattern space to the screen | ||
| -l # | Often used with COMMANDl (lowercase "L") to specify the length of each line | # is a number | |
| -r | Use extended regular expressions | ||
| --help | Display the command's built-in help. | ||
Some options of sed can function independently, but some options are not meaningful when used alone. For example, -n or -l need to be combined with other sed COMMANDs to be meaningful. The explanations for each option are as follows:
- -e: Execute the sed script syntax
Since sed is designed to execute its own script language, this option is the default and can be omitted if no other options are used. However, when dealing with multiple search and replace patterns or when multiple COMMANDs are combined, the -e option must be used.
Examples:$ echo 'this is a pen' | sed -e 's/t/T/' -e 's/pen/&cil/' ←Change "t" to "T" and "pen" to "pencil"
This is a pencil
$ sed -e 's/a/A/' -e '/this/ q' -e 'l' MyFile ←Using multiple sed COMMANDs with the -e option
(This example changes "a" to "A" in the file "MyFile" until a line contains the string "this" and then ends and lists non-printable characters.)
- -f: Use an external script file to execute
If sed has multiple tasks to perform, you can write each task in a separate external script file and then use the "-f" option to specify that external script file. This approach allows easy modification of rules by simply editing the external script file or creating multiple script files to handle different requirements.
Examples:$ cat sed_scr ←For example, an external script file named "sed_scr" changes a~d to uppercase
s/a/A/g
s/b/B/g
s/c/C/g
s/d/D/g
$ echo 'abcdefg' | sed -f sed_scr
ABCDefg
Examples:$ sed -f sed_scr < MyFile > TargetFile ←Using the external script file "sed_scr" to process "MyFile" and save the output in "TargetFile"
- -n: Do not output the pattern space to the screen
Since sed sends the contents of the pattern space to the screen and clears it after processing each line, using the "-n" option alone would result in no output to the screen. Thus, the "-n" option is generally used in combination with other sed FLAGs. Usually, it is combined with the sed FLAG " p" to print only the current pattern space (patterns that match the search criteria) to the screen. This behavior can replace the functionality of grep.
Examples:$ ls -d /etc/* | sed -n '/[A-Z][0-9]/ p' ←Using the -n option with the "p" flag to list lines matching the pattern (similar to "grep" command)
/etc/X11
$ echo -e 'Line1\nLine2\nLine3' | sed -n 's/Line2/Line two/p' ←Printing only the lines that have changed
Line two
- -l: Specify the length of each line
The "-l" option (lowercase "l") is used in conjunction with the "l" COMMAND (lowercase "l"). The sed COMMAND"l" is used to display some ASCII control characters as \a, \b, \t. However, most ASCII control characters are used for text positioning or formatting, and printing them may affect the length of the lines. Therefore, the "-l" option is used to specify the output length on the screen.
Examples:$ echo -e 'This\tIs\tA\tDog' | sed -nl 10 'l' ←Specify the line wrap length as 10
This\tIs\
\tA\tDog$
- -r: Interpret using extended regular expressions
By default, sed interprets patterns using regular expressions. With the -r option, it interprets patterns using extended regular expressions. In extended regular expressions, characters like "?" and "+" are treated as meta-characters, giving different interpretation results.
Examples:$ echo 'Why an apple $9.99?' | sed 's/99?/88/g' ←Change the string "99?" to "88"
Why an apple $9.88
↑In this example, the pattern "99?" is treated as a normal regular expression. However, with the -r option, it is interpreted using extended regular expressions (as in the following example).
$ echo 'Why an apple $9.99?' | sed -r 's/99?/88/g' ← Using the -r option for extended regular expressions
Why an apple $88.88?
The sed FLAGS mainly control the behavior of replacing patterns. We have already used the "g" (global replacement) and "p" (print) flags earlier. These two flags are the most commonly used, and the others are less common. Let's understand them, but keep in mind that all the FLAGS' purposes are as follows:
| Sed Flags | |
| [g][ number] | Global replacement or specify which occurrence to replace |
| I | Ignore case in the pattern |
| p | Print the current pattern space |
| w | Write to a file |
- g: Global replacement.
By default, sed only replaces the first occurrence of the search/replace pattern on each line and then moves on to the next line. If this FLAG is used, all occurrences are searched and replaced.
Examples:$ echo 'this is an issue' | sed 's/is/IS/' ←"is"→"IS", but by default, only the first occurrence is replaced
$ echo 'this is an issue' | sed 's/is/IS/g' ←Using the "g" FLAG for global replacement
thIS IS an ISsue
The FLAG can also be used with a number, which indicates replacing only the Nth occurrence of the pattern.
Examples:$ echo 'aaaaa aaaaa' | sed 's/a/A/3' ←Replace only the 3rd occurrence
aaAaa aaaaa
The g FLAG can be combined with a number. Adding a number before the g FLAG, such as 3g, means replacing only the 3rd occurrence.
Examples:$ echo 'aaaaa aaaaa' | sed 's/a/A/3g' ←Replace starting from the 3rd occurrence
aaAAA AAAAA
- I: Ignore case in the pattern.
This FLAG treats the pattern case-insensitively.
Examples:$ echo 'this is an apple' | sed 's/APPLE/banana/I'
this is an banana
- p: Print current pattern space.
Without this FLAG, sed only outputs the pattern space. With the p FLAG, the current pattern space is printed. Usually, this FLAG works in conjunction with the "-n" option to print only the matching pattern (current pattern space).
Examples:$ echo 'this is a pen' | sed 's/pen/pencil/p'
this is a pencil ←This line outputs the contents of the pattern space
this is a pencil ←This line outputs the contents of the current pattern space
$ echo -e 'Line1\nLine2\nLine3' | sed -n '/[13]/p' ←Using the -n option with FLAG "p" to list only matching patterns
Line 1
Line 3
- w: Write to a file
Similar to the "p" FLAG, the difference is that "w" FLAG writes the current pattern space to a file specified by FILE.
Examples:$ man cp | sed 's/copy/{&}/w cp.txt' ←Write occurrences of "copy" from the man page to the file "cp.txt"
Examples:
| $ man cp | sed -n 's/COPY/{&}/Igpw cp.txt' ←When using multiple FLAGS, file-related FLAGS (such as "w") must be placed at the end |
sed is quite programmable, and you can accomplish most text modification tasks without knowing any other programming language, as long as you understand sed. Like any other programming language, sed has flow control features. Fortunately, the flow control in sed is relatively simple and limited compared to other programming languages.
Flow control in sed is part of sed COMMAND and is treated as a separate entity. I will explain the syntax and usage of each flow control feature separately.
- ! and #: Disable and Comment
In an external sed script file, you can temporarily disable a line from execution by adding a "!" in front of it. Lines starting with "#" are treated as comments and are not executed.
Examples:$ cat sed_scr1
# conver a..d to A..D ← This line is a comment and won't be executed
s/a/A/g
!s/b/B/g #← Lines starting with "!" won't be executed
#s/c/C/g #← Lines starting with "#" are comments and won't be executed
s/d/D/g
$ echo 'abcdefg' | sed -f sed_scr1
AbcDefg
The "!" can also be used with commands to negate their actions. For example, sed '/pattern/ d' deletes lines that match the pattern, while sed '/pattern/ !d' deletes lines that don't match the pattern.
Examples:$ sed -n '10,15 !p' MyFile ← Do not output lines 10 to 15 of the file
$ cat MyFile | sed -n '/Apple/ !=' ← List line numbers where the string "Apple" is not present
- {}: Command package
sed treats the contents inside curly braces "{}" as a command package, akin to a combo meal at McDonald's that includes fries, burger, and a drink—all in one. The content inside the curly braces forms a cohesive unit, and you can decide what commands to include in this package.For example, let's rewrite the previous example using a command package:
Examples:$ cat sed_scr2
# grouping with {}
{ #←Command package starts
s/a/A/g
!s/b/B/g
#s/c/C/g
s/d/D/g
} #←Command package ends
$ echo 'abcdefg' | sed -f sed_scr2
AbcDefg
At first glance, using a command package in this example may seem redundant because enclosing the commands in curly braces doesn't seem to change the result. However, the real advantage of using a command package comes into play when you have an address range. After an address range, only one command is allowed. By using a command package, you can bundle multiple commands together as a single unit. Let's see an example where we process only lines 1 to 3 of a file using a command package:
Examples:$ cat sed_scr3
# grouping with {}
1,3 {
s/a/A/g
!s/b/B/g
#s/c/C/g
s/d/D/g
}
$ head 3 /etc/passwd | sed -f sed_scr3
root:x:0:0:root:/root:/bin/bAsh
bin:x:1:1:bin:/bin:/sbin/nologin
DAemon:x:2:2:DAemon:/sbin:/sbin/nologin
this example, the commands 's/a/A/g', '!s/b/B/g', and 's/d/D/g' are grouped inside the command package "{}". They are only applied to lines 1 to 3 of the input file, "/etc/passwd".
A crucial point to note in the syntax is that the address range and the opening curly brace "{" must be on the same line. This is because the address range is followed by a command or the beginning of a command package, marked by the opening curly brace "{".
Attempting to write the curly brace on the next line will result in a syntax error, as shown in this incorrect representation:
Incorrect Example:
$ cat sed_scr4
/hello/
{ #Error! The opening curly brace for the command package should be on the same line as the address range.
s/a/A/
}
Finally, it's worth mentioning that you can also nest multiple curly braces "{} " to create nested command packages, like in this example where we process lines from 10 to the end, and within that range, we process lines between "chapter 1" and "chapter 2," changing "a" to "A" and "b" to "B"::
例:$ cat sed_scr5
# grouping with nest burly braces
10,$ {
/chapter 1/,/chapter 2/ {
s/a/A/g
s/b/B/g
}
}
- label: Label.
A label in sed is represented by a colon ":" followed by any visible characters or symbols. It provides entry points for sed COMMAND "b"," "t, or" T".
- b label: Jump to label
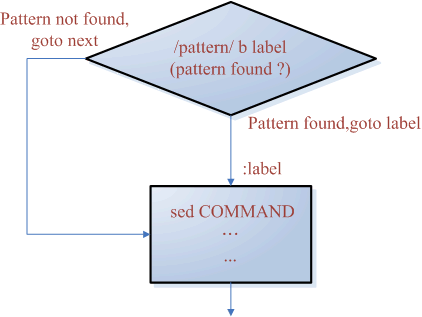
The command "b" followed by a label (e.g., "b upper") is used to jump to the specified label. Jumping can be categorized as "unconditional jump" and "pattern-conditioned jump."For example, "b upper" represents an unconditional jump to the label "upper," meaning the program execution will immediately jump to the specified label "upper" regardless of any conditions.
On the other hand, "/pattern/ upper" represents a pattern-conditioned jump. It means that if the pattern "pattern" is matched, the program will jump to the label "upper." Otherwise, it will execute the next line.
The flowchart for this behavior is as follows:
Examples:$ cat sed_scr6
# if pattern 'google' found,char "a"->"A" else "b"->"B"
/google/ b capitalA #← If pattern 'google' is found, jump to label 'capitalA'
{
s/b/B/g
b end #← Unconditionally jump to label 'end'
}
:capitalA #← Label 'capitalA'
{
s/a/A/g
}
:end #← Label 'end
$ echo -e 'google abc\nyahoo abc' | sed -f sed_scr6
google Abc
yahoo aBc
- t label: Branch to label if a substitution is successfuf
t label allows branching to the specified label if a substitution is successful (pattern is found and replaced). Otherwise, it executes the next line.
Examples:$ cat sed_scr7
s/g..g../GOOGLE/g
t capitalA #← Jump to label 'capitalA' if the substitution is successful, otherwise execute the next line
b end
:capitalA
s/a/A/g
:end
$ echo -e 'google abc\nyahoo abc' | sed -f sed_scr7
GOOGLE Abc
yahoo abc
- T label: Branch to label if a substitution is unsuccessful
T label allows branching to the specified label if a substitution is unsuccessful (pattern is not found or not replaced). Otherwise, it executes the next line.
Examples:$ cat sed_scr8
s/g..g../GOOGLE/g
T end #Jump to label 'end' if the substitution is unsuccessful, otherwise execute the next line
s/a/A/g
:end
$ echo -e 'google abc\nyahoo abc' | sed -f sed_scr8
GOOGLE Abc
yahoo abc
Previously, we have used the sed COMMAND "s" because sed is powerful, there are many related COMMANDs, and fortunately, most of the COMMANDs are similar to vi.
The possible sed commands are as follows:| sed COMMAND | Address |
|
Note | |
| :label | label | Reference Flow Control | ||
| # | Comment | Reference Flow Control | ||
| ! | Disable | Reference Flow Control | ||
| {} | Command package | Reference Flow Control | ||
| b label | b label: J | Reference Flow Control | ||
| t label | Branch to label if a substitution is successfuf | Reference Flow Control | ||
| T label | T label: Branch to label if a substitution is unsuccessful | Reference Flow Control | ||
| = | scope | Print line numbers | ||
| a , i or a\, i\ | scope | Insert text | ||
| c or c\ | scope | Replace lines | ||
| d | scope | Delete pattern space or specified lines | ||
| D | scope | Delete the first character of the pattern space up to the newline | ||
| g | scope | Copy the hold space to the pattern space | ||
| G | scope | Append the hold space to the pattern space | ||
| h | scope | Copy the pattern space to the hold space | ||
| H | scope | Append the pattern space to the hold space | ||
| l | scope | Force printing of hidden characters | ||
| n | scope | Read the next line | ||
| N | scope | Append the next line to the pattern space | ||
| p | scope | Print current pattern space | ||
| P | scope | Print from the beginning of the current pattern space up to the first newline | ||
| q | single address | Immediately exit sed | ||
| Q | single address | Exit sed immediately without printing the current pattern space | ||
| r | single address | Insert the contents of a file | ||
| s | scope | search-and-replace | ||
| w | scope | Write the current pattern space to a file | ||
| x | scope | Exchange the contents of the pattern space with the contents of the hold space. | ||
| y | scope | Translate characters |
The individual sed commands are explained as follows: :
- =: Print line numbers
Sometimes we want to know on which line a certain pattern appears in a file, and it is quite convenient to use "=" to print it.
Examples:$ sed -n '/home/=' /etc/passwd ← List line numbers in the file "/etc/passwd" that contain the string "home"
37
38
39
Since in regular expressions, "$" represents the end or last position, we can use "$=" to list how many lines a file has.
Examples:$ man sed | sed -n '$=' ← List how many lines the sed manual page has
261
- a, i or a\, i\: Insert text
sed can insert text before or after a certain line or the line matching a pattern. To insert after a certain line or pattern, use the command "a", and to insert before it, use "i".
Examples:$ echo -e 'Line1\nLine2\nLine3' | sed '/Line2/ aINSERT' ← Insert "INSERT" after the line containing "Line2".
Line1
Line2
INSERT ← Inserted line
Line3
$ sed '6,$ aHello' MyFile ← Insert "Hello" after lines 6 to the end in the file "MyFile"
If you want to insert multiple lines, simply use the newline character "\n".
Examples:$ echo -e 'Apple\nBanana\nCoconut' | sed '3 iOrange\nDurian' ← Insert two lines above the third line
Apple
Banana
Orange ←Inserted line
Durian ←Inserted line
Cocount
If you write it in an external script file and want to insert the text written after the command "a" or "i" in the next line, you should write it as "a" and "i", and append "\n" to the inserted text to represent a newline.
Examples:$ cat sed_scr9
/pattern/ a\
Insert line1 \
Insert Line2
- c or c\: Replace lines
Replace a range of lines or lines that match a pattern with new lines.
Examples:$ echo -e 'Line1\nLine2\nLine3' | sed '/2$/ cREPLACE LINE' ← Replace the line ending with "2" with "REPLACE LINE". Line1
Line1
REPLACE LINE
Line3
$ echo -e '1\n2\n3\n4\n5' | sed '1,3 cREPLACE 1-3' ←Replace multiple lines with one line.
REPLACE 1-3
4
5
The usage of COMMAND "c" is similar to the insert COMMAND "a" or "i", and you can use the newline character "\n" or "c".
- d: Delete pattern space or specified lines
Examples:$ sed '4,8 d/' MyFile ←Delete lines 4 to 8.
$ sed '4,8 !d/' MyFile ←Keep lines 4 to 8 and delete the rest
$ sed '/pattern/ d' MyFile ←Delete lines that match the pattern
$ sed '/pattern1/,/pattern2/ d' MyFile ←Delete all lines between pattern1 and pattern2 (inclusive)
$ sed '/^$/ d' ←Delete empty lines
- p: Print current pattern space
Normally used with the option "-n" because "-n" suppresses output of the pattern space to the screen. The COMMAND "p" is used to print the current pattern space, so when used together, it prints patterns that match the search pattern.
Examples:$ sed -n '5,12 p' file ← Print lines 5 to 12 of "file"
$ sed -n '/regex1/,/regex2/ p' file ← Print lines between regex1 and regex2 (inclusive) in "file".
- N, D, and P: Multi-line editing
The sed commands "N", "D", and "P" (all in uppercase) are mainly used for multi-line editing, and their functions are as follows:
- N: Append the next line to the pattern space
In sed, each line is read one at a time, and the trailing newline is removed and stored in the pattern space. When processing the next line, the contents of the pattern space are cleared and replaced with the current line.The "N" command, however, appends the content of the next line to the existing pattern space without clearing it. The two sets of data are separated by the newline character "\n" (ASCII = 0AHEX).
For example, if you have use the command echo -e 'LineA\nLineB' | sed 'N , the pattern space will contain:
This allows you to process multiple lines together in the pattern space.L i n e A \n L i n e B
Example:$ echo -e 'LineA\nLineB' | sed -e 'N' -e 's/\n/+/' ←Using "N" to read the next line and replacing the newline character "\n" with another string
LineA+LineB
The above example is commonly used to merge multiple lines.
- D: Delete from the beginning of the pattern space to the first newline
The "D" COMMAND in sed deletes the content of the pattern space from the beginning up to the first newline character "\n". If the pattern space contains multiple lines, only the first line will be deleted.For example, if the pattern space contains the following content:
'LineA\nLineB\nLineC'L i n e A \n L i n e B \n L i n e C
After executing the "D" command, the pattern space will be:LineA\nL i n e B \n L i n e C
Example:$ echo -e 'LineA\nLineB\nLineC' | sed -e 'N' -e 'N' -e 'D' ←Using "N" twice to read the next two lines, then "D" to delete the first line
LineB
LineC
- P: Print from the beginning of the current pattern space up to the first newline.
The "P" command in sed behaves similarly to the "D" command, but instead of deleting the content, it prints the content from the beginning of the pattern space up to the first newline character "\n".
Example:$ echo -e 'LineA\nLineB\nLineC' | sed -e 'N' -e 'N' -ne 'P'
LineA
Examples:$ cat sed_scr10
/ID/{
N #if matching "ID" append the next line
/NAME/ {
N #if 2nd line matching "NAME" append next line again
/ADDRESS/ {
D #delete 1st matched line
}
}
}
$ echo -e 'ID:123\nNAME:abc\nADDRESS:taipei' | sed -f sed_scr10
NAME:abc ←I← The line with "ID" was deleted
ADDRESS:taipei
$ echo -e 'ID:123\nSEX:m\nADDRESS:taipei' | sed -f sed_scr10
ID:123 ← If the patterns "ID", "NAME", and "ADDRESS" are not in sequential and adjacent lines, they will not be deleted
SEX:m
ADDRESS:taipei
- N: Append the next line to the pattern space
- h, H, g, G, and x: Exchanging pattern space and hold space
Before explaining these commands, let's understand the concept of sed commands h/H, g/G, and x, which involve the use of "hold space." Hold space is another buffer, similar to pattern space, but its content is not directly output to the screen. Instead, it is used to provide certain commands (such as g/G/h/H/x) with a way to exchange content between pattern space and hold space, enhancing the editing capabilities of the file. The process is as follows.
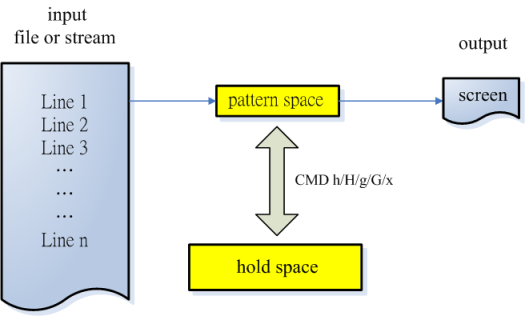
The flow of interaction between pattern space and hold space is as follows:
這幾個和 hold space 有關的 COMMAND 說明各名下:
- h: Copy the pattern space to the hold space
- H: Append the pattern space to the hold space
For example, if the hold space contains:L i n e A
And the pattern space contains:L i n e B
After executing the command "H," the hold space will be:
L i n e A \n L i n e B - g: Copy the hold space to the pattern space
- G: Append the hold space to the pattern space
Examples:$ cat sed_scr11
/ID/{
h # if matching "ID" pattern-space copy to hold-space
n # read next line
/NAME/ {
G # append hold-space to pattern-space
}
}
p # print the current-pattern-space
$ echo -e 'ID:123\nNAME:abc' | sed -nf sed_scr11
NAME:abc
ID:123
The combination of multi-line editing commands (such as "N," "n," "D," and "P") with hold space exchange commands can create many unexpected and useful functionalities.[note]
- h: Copy the pattern space to the hold space
- l: Force printing of hidden characters
Sometimes, you may encounter situations where a certain string is present in a file, but using sed or grep does not match it. One of the most likely reasons for this is that the file contains non-displayable characters such as "\a" or "\t" as escape sequences, or there are extra spaces before the newline character. The "l" command in sed is a useful debugging tool to reveal such hidden characters.
$ echo -e 'as can\aner can can a can '
as canner can can a can ←Output appears normal
$ echo -e 'as can\aner can can a can ' | sed -n '/can$ /p' ←The extra space after the last "can" will cause the regex "can$" to not match
$ echo -e 'as can\aner can can a can ' | sed -n '/canner /p' ←The non-displayable "\a" character prevents matching
$ echo -e 'as can\aner can can a can ' | sed -n 'l' ←Using the "l" command to reveal hidden characters
$ as can\aner can can a can $
So sed 'l' is a very useful debug tool, another usage of COMMAND "l" is to use it with option -l
- q or Q: Immediately exit sed
Using sed q or sed Q, you can specify to exit after a certain line number or after a match to a specific pattern. The difference between COMMAND "Q" and "q" is evident in the following examples.
Examples:$ ls -l / | sed '/dev/ q'
total 142
drwxr-xr-x 2 root root 4096 2012-07-04 19:48 bin
drwxr-xr-x 4 root root 1024 2012-06-09 01:30 boot
drwxr-xr-x 13 root root 4060 2013-10-31 19:50 dev
$ ls -l / | sed '/dev/ Q'
total 142
drwxr-xr-x 2 root root 4096 2012-07-04 19:48 bin
drwxr-xr-x 4 root root 1024 2012-06-09 01:30 boot
Examples:$ sed '10 q' MyFile ←Display the first 10 lines of a file, equivalent to the "head -n" command
$ sed -e 's/a/A/' -e '/Hello/ q' MyFile ←Search and replace, but quit when "Hello" is encountered
In summary, both "q" and "Q" commands are used to exit the sed program, but "q" will print the current pattern space before exiting, while "Q" will not print the current pattern space and immediately quit
- n: Read the next line
The "n" command reads the next line and replaces the current pattern space with it.
Examples:
During multi-line editing or when using COMMAND "h" to access the hold space, the "n" command is often a necessary element.$ echo -e 'LineA\nLineB' | sed -e 'n' -ne 'p'
LineB
- r: Insert the contents of a file
The "r" command behaves similarly to the "a" command but differs in that it inserts the content from a file.
Examples:$ sed '3 r INSERT.txt' MyFile ←Insert the content of the file "INSERT.txt" after the third line of "MyFile"
$ cat MyFile | sed '/ch1/,/ch2/ r INSERT.txt' ←Insert the content of "INSERT.txt" between the patterns "ch1" and "ch2"
$ sed '/ch1/ r INSERT.txt' MyFile ←Insert the content of the file "INSERT.txt" after the line that matches the pattern "ch1
- w: Write the current pattern space to a file
While redirection is more flexible for writing to files, using COMMAND "w" becomes necessary when the file being processed and the file to be written are the same.
Examples:$ cat fileA | sed 's/i/I/g' > fileB ←Recommended to use redirection if the processed file and the output file are different
$ cat fileA | sed 's/i/I/g w fileA' ←CCOMMAND "w" is useful when the processed file and the output file are the same
- y: Translate characters
If you want to convert all lowercase characters in a file to uppercase, using the "s" command might be cumbersome. In such cases, the "y" command in sed can easily accomplish the task.
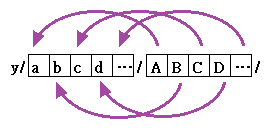
For example, "y/abcd.../ABCD.../" means that each character in the second set is replaced by the corresponding character in the first set.
Examples:$ echo abcdefg | sed 'y/abc/ABC/'
ABCdefg
$ echo 'john smith' | sed 'y/nh/#&/'
jo&# smit&
$ echo '(2+3)*4' | sed 'y/()*/[]X/'
[2+3]X4